CES 2026 :
Meet our leadership team from Jan 6 to 9 in Las Vegas to
unlock Engineering impact beyond AI hype.
Platform
Customer Stories
Resources
Executive Perspectives
Company News
Tech Reads
Research
Webinars
View all resources
About
Who We Are
Media Coverage
Press Releases
Events
Careers
Request a demo
Resources
Stay updated with the latest AI news, insights, case studies, and product innovations.
Blog
AI R&D: How Artificial Intelligence Is Transforming Research and Development
Read More
Filter
Reset
Category
Press Releases
Blog
Events
Customer Stories
Webinars
Research
Topics
Executive Perspectives
Tech Reads
Company News
Industry
Automotive
Aerospace
Marine
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.
Customer Stories
Company News
Automotive
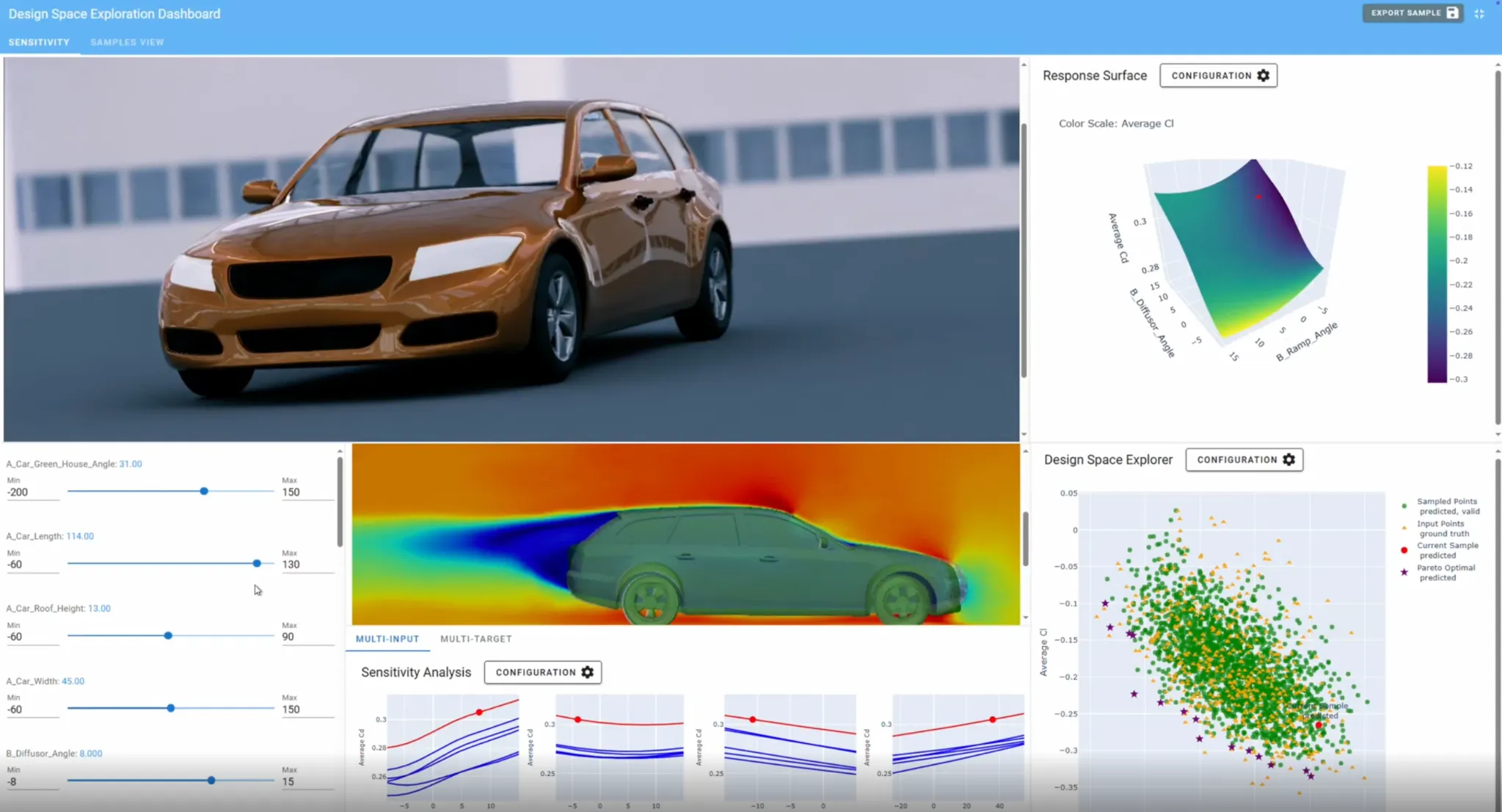
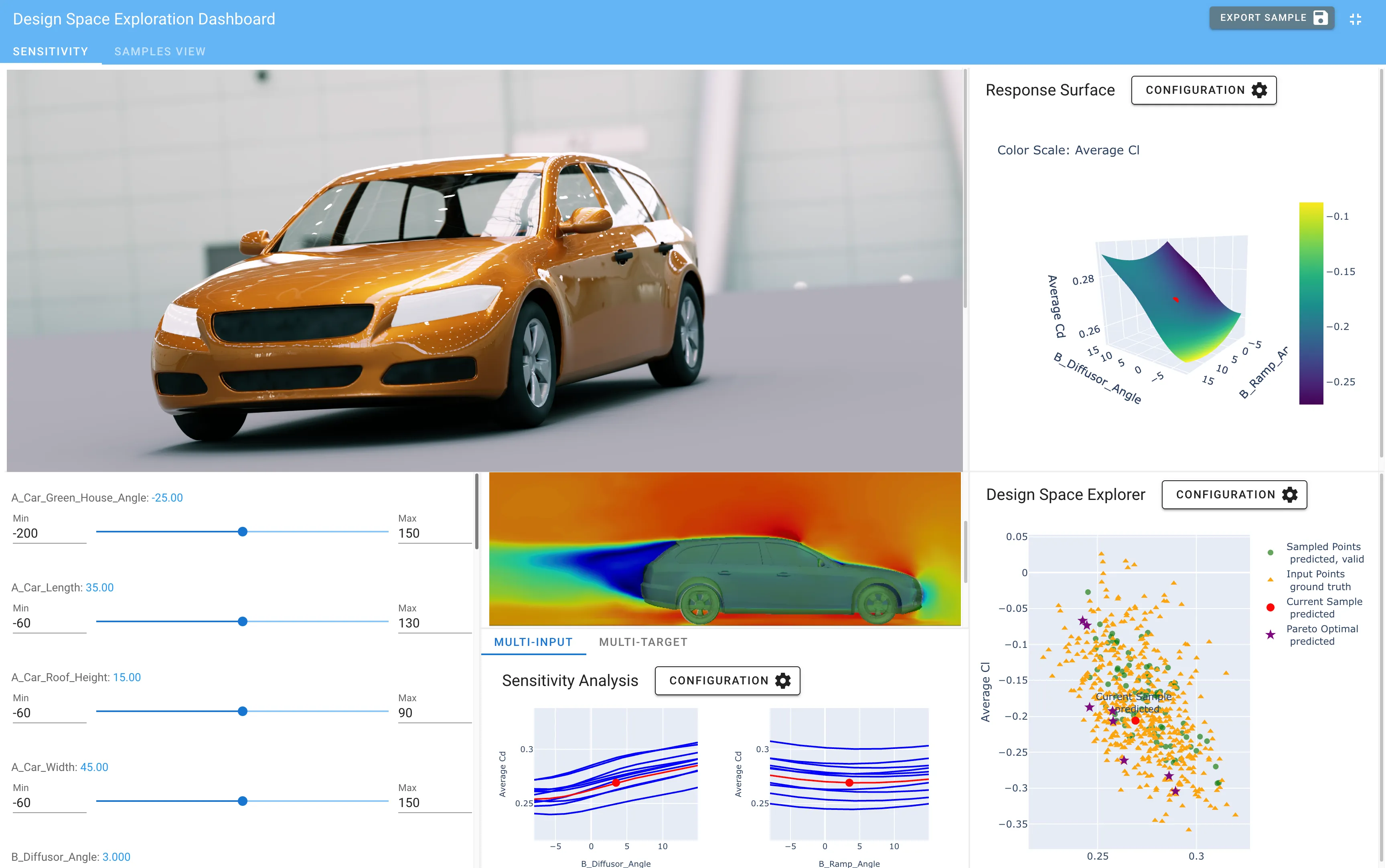
AI-Native Aerodynamic Engineering in Practice with JLR - From NVIDIA GTC to Production
Blog
Company News
CES 2026 Confirms the Shift Toward Engineering Intelligence
Customer Stories
Company News
Automotive
Antolin and Neural Concept join forces to redefine Automotive Interior Design with AI-Driven Engineering
Press Releases
Company News
Neural Concept Introduces a Physics- and Geometry-Aware AI Design Copilot, Extending Its Established Engineering AI Platform
Blog
Company News
Inside Neural Concept Connect 2025: Shaping the Future of Engineering Intelligence
Press Releases
Company News
Neural Concept Closes $100M Funding Round Led by Growth Equity at Goldman Sachs Alternatives to Scale AI-Native Engineering
Blog
Tech Reads
From Dataset to Design Impact: How Neural Concept Set a New Benchmark on MIT’s DrivAerNet++
Blog
Executive Perspectives
Trust and the Innovation Paradox
Blog
Executive Perspectives
Engineering Experience in the Age of AI
Blog
Company News
Empowering the Builders of Engineering Intelligence
Oct 29, 2025
Press Releases
Neural Concept Accelerates Integrated AI Adoption With 100% Enterprise Growth
Blog
Executive Perspectives
Finding the Path to Value in Engineering AI – Why We Need to Rethink Benchmarking
Press Releases
From Raw Data To State-of-the-art Results On Aerodynamics ML With Neural Concept
Customer Stories
MAHLE uses Neural Concept to design a ground-breaking new radial blower for automotive air conditioning systems
Blog
Executive Perspectives
Engineering: AI’s last frontier?
Customer Stories
Visa Cash App Racing Bulls (VCARB) Formula One™ Team Accelerates Racing Car Design with Neural Concept’s Engineering AI
Jun 4, 2025
Customer Stories
Neural Concept and OPmobility Announce Partnership and Demonstrate New AI-Driven Designs for Hybrid, Hydrogen and Complete Vehicles Bodies at CES 2025
Jan 6, 2025
Blog
Tech Reads
Breaking Down Silos in Engineering Design Teams with AI
Blog
Tech Reads
AI in Vehicle Safety Systems - Transforming for Safer Roads
Blog
Tech Reads
Understanding the Engineering Product Development Life Cycle
Blog
Tech Reads
What Are Constraints in Engineering - Overcoming Design Barriers
Blog
Tech Reads
Industrial vs Mechanical Engineering: Skills, Roles, Opportunities Turn on screen reader support
Blog
Tech Reads
Automotive Digital Transformation - Trends and future predictions
Blog
Tech Reads
Self Driving Car Machine Learning Fully Explained
Blog
Tech Reads
Enhancing Design Efficiency with Artificial Intelligence CAD Solutions
Blog
Tech Reads
Preventive vs Predictive Maintenance: Key Differences Explained
Customer Stories
Revolutionizing Pedestrian Safety with AI: General Motors with Neural Concept
Blog
Company News
Empowering the builders of tomorrow’s Engineering in India with OPmobility
Customer Stories
Neural Concept Wins American Axle & Manufacturing’s (AAM) Innovation Excellence Award for Pioneering AI-Driven Product Design
Blog
Tech Reads
Collaborative Design Process: Steps, Benefits & AI Integration
Load more






.webp)






.webp)
.webp)









.webp)

.webp)