The Importance of Uncertainty Quantification for Deep Learning Models
Assessing our uncertainty has a pivotal role in making informed decisions. Wouldn't it always be ideal to have information about the confidence level in our predictions? This would give us a much stronger influence in the decision-making processes or reduce our risk if we are in charge of the decision.
Uncertainty estimates for a predictive model are crucial in engineering systems design, analysis, and testing. The article will focus on predictive models in complex systems such as engineering, with predictions coming from 3D CAE (Computer-Aided Engineering) and data-driven artificial intelligence (AI).
When issuing an AI prediction with a machine learning agent, one can question how much a human or a machine learning agent is sure about the prediction. This article will focus on building predictive models that surrogate more resource-intensive CAE models and uncertainty quantification in deep learning for designers
The first two questions we will address in the following are:
- What types of uncertainty quantification are we dealing with, and is predictive uncertainty related to predictive accuracy?
- What are the models representing model uncertainty?
Is Uncertainty the Same as Low Accuracy?
The answer is: No!
The concepts of accuracy and uncertainty are related but distinct - a model can have high accuracy but still have high uncertainty, or vice-versa.
- Model uncertainty refers to the degree of confidence in a model's predictions. It represents the model's possible outcomes given the input data.
- On the other hand, model accuracy measures how closely a model's predicted output matches the output for a given set of inputs. In other words, accuracy measures the correctness of a model's predictions.
Therefore, please note that a model based on limited data could have high accuracy but still have high uncertainty.
Representing Model Uncertainty
As engineers, we must understand the concept of model uncertainty and how predictive uncertainty quantification can be expressed for our models.
Model uncertainty arises from the limitations and approximations in our models, and it can significantly impact the predictions and decisions made based on these models.
When building a machine learning-based predictive model, it is essential to consider the sources of uncertainty that may be present. Two main types of uncertainty quantification are aleatoric and epistemic uncertainty.
Review of Uncertainty Quantification
Aleatoric uncertainty is randomness or noise inherent in the data, while epistemic uncertainty is due to a lack of knowledge about the model or its parameters. Aleatoric uncertainty is random, while epistemic uncertainty is due to a lack of information.
Aleatoric uncertainty Quantification
This type of uncertainty is typically modelled as a probability distribution over the output space. It can be mathematically represented by a likelihood function, which gives the probability of observing the data given the model's parameters. In other words, it measures the randomness in the data given the model's assumptions. For example, in a regression problem, we can represent the predictive uncertainty of the model with y = f(x) + ε where y is the output, f(x) is the true underlying function, and ε is the noise term.
Epistemic uncertainty Quantification
This uncertainty can be reduced by gathering more data or increasing the model's capacity. It can be mathematically represented by a prior probability distribution over the model's parameters.
For example, in Bayesian neural networks, epistemic uncertainty quantification is represented by the prior probability distribution over the network weights.
This can be mathematically represented by a probability density function (pdf) p=p(w) for the weights w of the network, where w is a vector of all the weights in the network. The prior pdf represents our initial beliefs about the distribution of the weights before any data is seen. For example, a common choice for the prior pdf is a Gaussian distribution with a mean zero and a certain precision (inverse of the variance) parameter. This prior distribution is placed on the weights to reflect the uncertainty in the initial weight values before any data is observed.
Given the observations, the likelihood function and the prior, Bayesian networks use Bayes' theorem to update the posterior distribution over the weights, representing our updated beliefs about the weights given the observed data. This updated distribution is used to predict unseen data and get the uncertainty quantification in these predictions.
CAE Simulation and Machine Learning Models
Machine learning (ML) and computer-aided engineering (CAE) simulation are both techniques used to analyze and make predictions about data. Still, their approach and the problems they are designed to solve differ.
Machine learning is a type of artificial intelligence that trains models to make predictions or decisions based on data. Machine learning algorithms can be trained on large amounts of data and learn to recognize patterns and relationships in the data. Machine learning can solve many problems, such as image recognition or predictive modelling.
CAE simulation, on the other hand, is a computer-based method of analyzing and predicting the performance of physical systems, such as mechanical, electrical, and fluid systems. CAE simulations use mathematical models and numerical methods to simulate the behaviour of a system. The results can then be utilized for engineering reports or for VR & AR visualization.
CAE simulations, thus, are physics-based and solve numerical equations on computational domains, mostly of industrial interest (CAD shapes). We will assume that CAE yields a reasonable estimation of a real-life behaviour and can therefore be assumed as “Ground Truth” (otherwise, it can be supplemented by experimental data). Similarly to the human brain, Deep Learning data-driven models learn by seeing examples and extracting information from these results. In our case, learnt examples are from CAD or various inputs (materials, boundary conditions etc.) and learnt results are CAE (or experimental). Hence, when facing a new unknown example, the model will predict the result in real-time based on the data used for its training.
What Types of Uncertainty Occur in CAE?
Computer-aided engineering (CAE), such as computational fluid dynamics (CFD), uses simulation software and computational techniques to analyze and design engineering systems. In some cases, CAE is used as the reference ground truth for deep learning predictions, meaning that the results from CAE simulations are considered the true or accurate representation of the analysed system.
The assumption of "no uncertainty" in the CAE results means that the simulations have been validated, and the software is considered perfectly reliable and accurate in representing the real-world behaviour of the system.
It is important, however, for completeness, to underline that several types of uncertainty can occur in conducting CAE simulations: Model, Discretization, Input, Parameter and finally, Numerical Uncertainty.
- Model Uncertainty refers to the uncertainty in the mathematical model used to simulate the physical system. This uncertainty can arise from a lack of knowledge of the underlying physical processes, the model's approximations, or the simplifications made to make the model more computationally tractable.
- Discretization Uncertainty refers to the uncertainty that arises from discretizing the continuous mathematical model into a finite number of elements. This uncertainty can arise from the choice of discretization method, the elements' size, and the elements' distribution.
- Input Uncertainty relates to uncertainty in the input data used to conduct the simulation. This can include uncertainty in the boundary conditions, initial conditions, and material properties.
- Parameter Uncertainty: This refers to the uncertainty in the parameters used in the mathematical model. This can include uncertainty in the coefficients, exponents, and other variables used in the model.
- Numerical Uncertainty is uncertainty that arises from the use of numerical methods to solve the mathematical model. This can include uncertainty from the choice of the numerical method, the size of the time step or spatial step, and the accuracy of the numerical solution.
The Mathematics of Physics and the Mathematics of Deep Learning
Before tackling uncertainty estimation for deep learning networks imitating CAE simulation, let us review the basic concepts from CAE and deep learning prediction.
In CAE simulations, a mathematical model of the engineering system is defined by a set of equations describing the system's behaviour.
For example, in CFD, the Navier-Stokes equations are used to describe the flow of a fluid. These equations can be written elegantly as ∂u/∂t + (u•∇)u = -∇p + ν∇²u (where u is the velocity vector, t is time, p is pressure, and ν is the kinematic viscosity of the fluid). Roughly speaking, the ambitious task of CFD is to solve those equations (giving the spatial 3D distributions of u and p and their evolution over time) for a specific domain (a physical object represented by CAD), boundary conditions (operating conditions), initial conditions and for given materials (one or more fluid phases), and other associated conditions (compressibility, heat transfer and so on).
Deep Learning models are part of the more generic Machine Learning and AI concepts. In deep learning models, the goal is to learn a mapping between inputs "x" and outputs "y". The first application of deep learning that comes to mind is the recognition of 2D images, as exemplified here. However, in the hands of Neural Concept, the concept was pushed to recognition of 3D CAD geometries in terms of CFD outputs (and other 3D simulations outputs, such as FEA for stress, crashworthiness or electromagnetism). The input-output relationship in its most generic form is represented mathematically as f(x) = y.
In the case of traditional artificial intelligence approaches, such as reduced order modelling, x is a set of parameters.
In the case of machine learning approaches such as the NCS approach inspired by Computer Vision, x is a non-parametric shape in 3D virtual space, i.e. properly speaking a CAD model.
Suppose now that CAE is used as the reference ground truth for deep learning models.
In that case, it is assumed that the CAE results, y_CAE, accurately represent the true behaviour of the system, and the deep learning model should learn to approximate (≈) this mapping: f(x) ≈ y_CAE
This mapping is highly "symbolic" but should convey what NCS is doing. The deep learning predictive model should produce outputs as close as possible to the CAE results, assuming that the CAE results are free of uncertainty.
However, as mentioned earlier, there can still be uncertainty in the CAE results. This uncertainty should be considered when evaluating the performance of the deep learning model.
Let us represent the input data to a deep learning model as x and the output as y. The reference ground truth data from CAE simulations can be represented as z. The assumption of no uncertainty in the CAE results can be mathematically represented as "z = f(x)", where f(x) is the analysis system's true or accurate representation. However, the actual output from the deep learning model can be represented as "y = g(x) + ε" where g(x) is the model's approximation of f(x); ε represents the error or uncertainty quantification of the model's output. This article has used the ε in the specific form of noise in the aleatoric uncertainty of a model.
Therefore, when CAE is used as the reference ground truth, it is assumed that the error term ε is negligible ε=0, meaning that the deep learning model's output y is very close to the true representation z.
What Types of Uncertainty Occur in Machine Learning?
In-domain, domain-shift, and out-of-domain uncertainty are different types of uncertainty that can occur in machine learning models.
- In-domain uncertainty refers to the uncertainty that arises when a model is applied to data that is similar to the data it was trained on. This type of uncertainty is often caused by noise or variability in the training data. It can be reduced by increasing the amount of training data or using more complex models.
- Domain-shift uncertainty arises when a model is applied to data drawn from a different distribution than the data it was trained on. This uncertainty is often caused by changes in the underlying data distribution, such as changes in the environment or the population of interest. It can be reduced using domain adaptation techniques, such as fine-tuning a pre-trained model on a new dataset or using domain-adversarial training methods.
- Out-of-domain uncertainty arises when a model is applied to data significantly different from the data it was trained on. This uncertainty is often caused by the model's inability to generalize to new, unseen data. It can be reduced using techniques such as data augmentation and transfer learning or models specifically designed to handle out-of-domain data, such as meta-learning.
Deep Learning Implementation for Simulation
When making a prediction, one can generally question human or artificial intelligence on how much she/it is sure about the prediction. The same is true for our Neural Network models.

NCS is a deep learning data-driven CAE tool to build and support surrogate models that produce outputs.
Deep Learning: Accuracy During the Training Phase
The surrogate model (trained neural network) undergoes extensive training and testing phases, having measurables such as L₁ (the mean average error) and R² (the coefficient of determination). However, an R² is a sort of “backwards-looking” measurable in the training/testing phase.
Engineers would like a “dynamic” way to assess if the prediction gives reliable uncertainty estimates during the neural network deployment phase. Suppose the neural network issues a signal of uncertainty above a certain predefined level. In that case, the human or artificial agent could decide to activate remediations such as submitting the neural network to new training (for efficiency, starting from the previous neural network and using Transfer Learning technology).
Uncertainty in Deep Learning: Uncertainty Quantification Example
Neural Concept has also worked extensively on uncertainty quantification in machine learning to help engineers during the deployment phase, facing epistemic uncertainty (degree of variation due to lack of knowledge of the model we are trying to predict).
As we will see in the next example in the figure, after uploading a given 3D CAD geometry, the engineer receives real-time predictions on the values of interest from the deep learning neural network with the values of interest a confidence index from the model.
Another typical application is generative design. In this case, NCS is an agent that may create geometric shapes far out of the initial design envelope. We wish to know if the predictions associated with the newly generated shapes are still reliable or if one needs more input/output samples for neural network re-training.
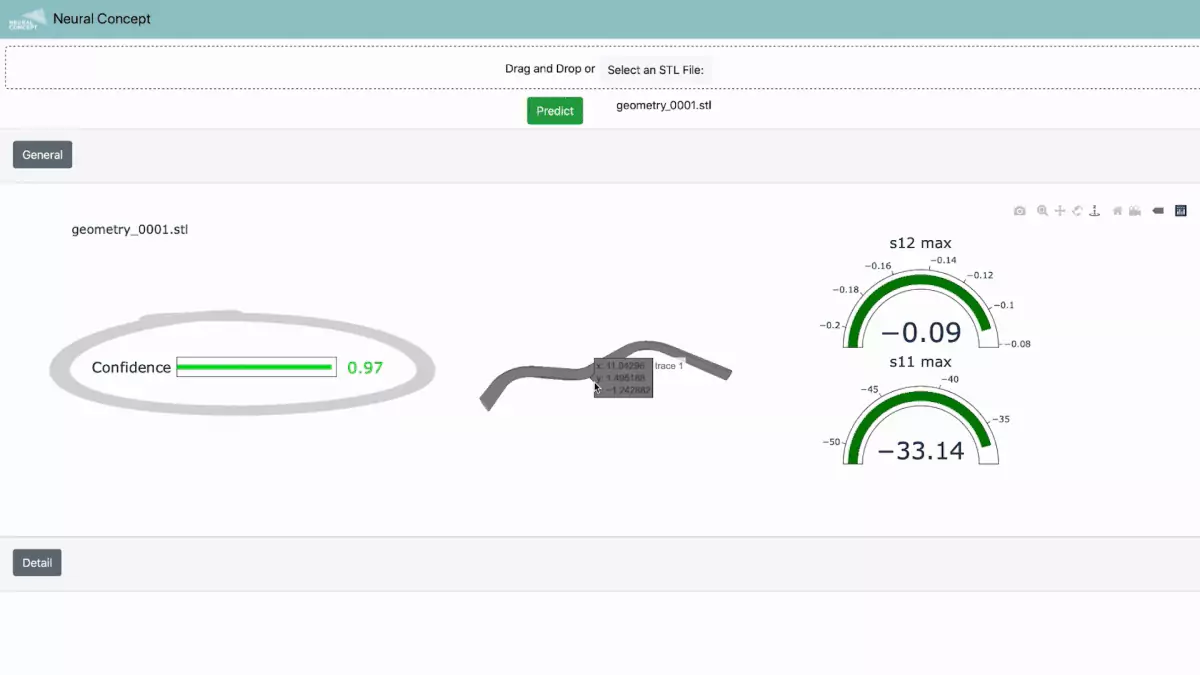
Use Case - Uncertainty Quantification in Antenna Prediction
The following application example of NCS for non-AI specialists (NCS Production), with a trained neural network embedded in a vertical application.
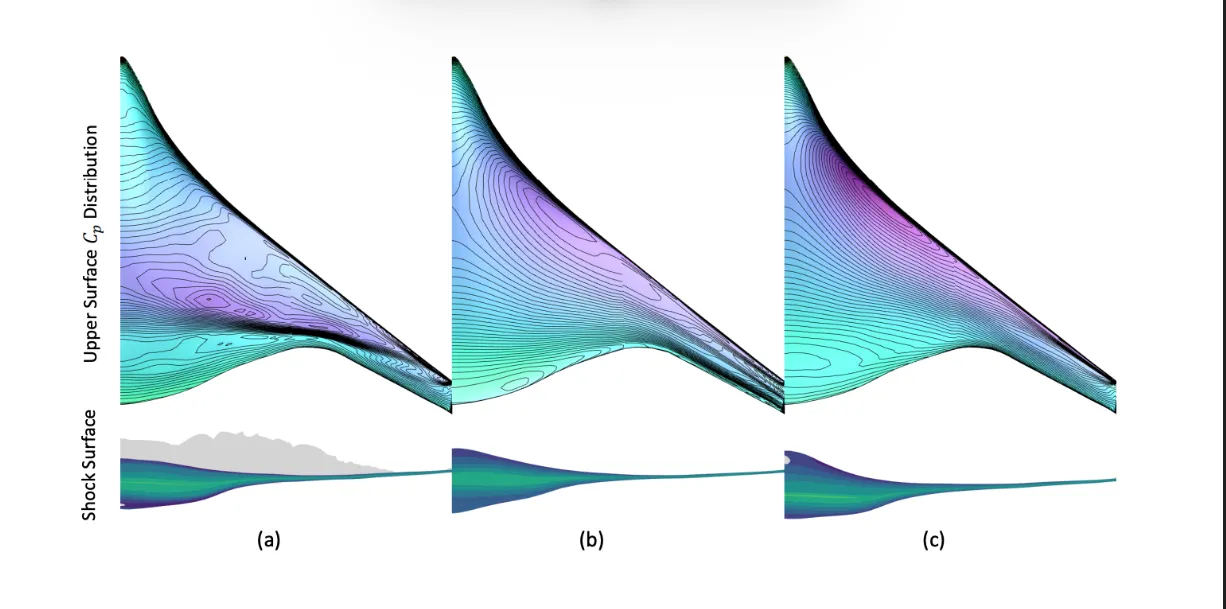
The application concerned prediction of scattering matrix elements for a waveguide, with a predictive model trained with 3D CAE electromagnetic data. But in addition to the prediction (shown in the figure by the numbers in the dashboard), it was important to predictive uncertainty quantification (also shown in the figure as confidence, available both as a single value and also as confidence intervals). Thus the user can both quantify the performance of the CAD shape and quantify uncertainty of the prediction. This is predictive uncertainty.
Users can, in conclusion, upload antenna geometries directly from their CAD software or non-parametric neutral format such as STL and instantly predict the values of interest for the analysis and the degree of confidence (in this case, 97%) - see figure below.
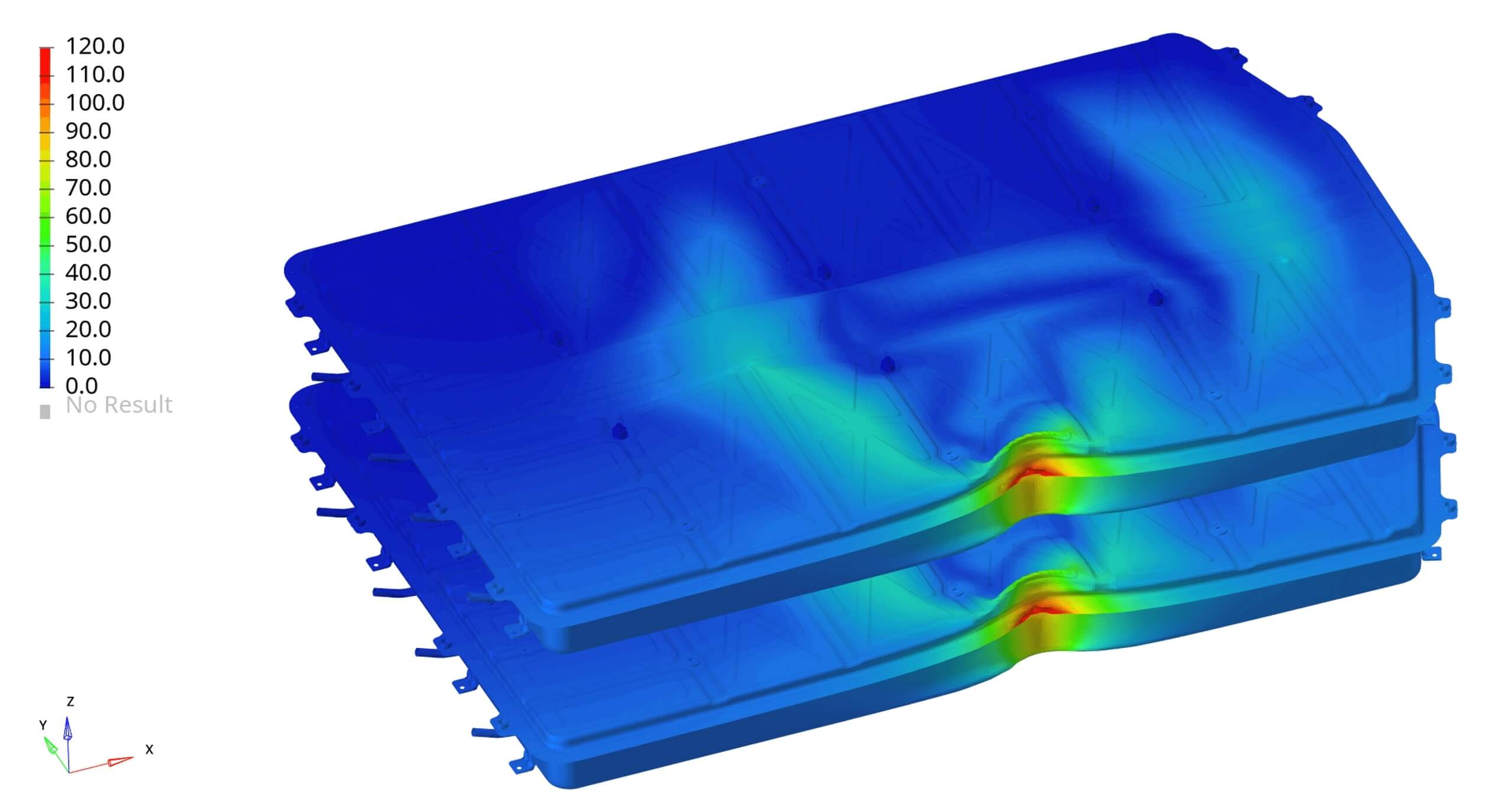
Use Case - Uncertainty Quantification in Crash Prediction
During testing and training phases, it is possible to compare visually (like in the image) or quantitatively NCS predictions with CAE predictions.
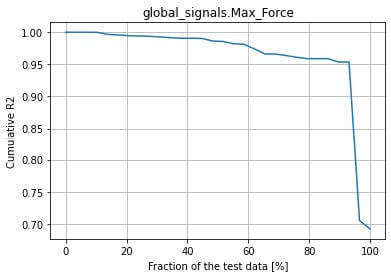
Using the NCS predictive uncertainty feature, we could sort the test data by the confidence index given by the model, from lowest to highest.
We then have a practical uncertainty estimation by showing the cumulative coefficient of determination R² based on the sorted samples. This allows quantifying uncertainty based on the test data.
New Uncertainty Quantification Methods: Masksembles for Predictive Uncertainty Estimation
Neural Concept’s staff collaborates on research topics on top of available software capabilities, mainly with EPFL (Lausanne – Switzerland).
This section will report some activity on a novel promising methodology called Masksembles.
Masksembles contains in itself the explanation of its technology, as follows more detailed:
An “ensemble”, in general, is a set of virtual copies of anything (in physics, a vessel under pressure; in AI, a neural network; in society, a collection of individuals) where the extension over multiple copies allows for several different physical states or network configurations. In particular, we are interested in epistemic uncertainty.
The “Deep Ensembles” technique consists of training an ensemble of deep neural networks on the same data with random initialization of each of the neural networks in the ensemble. By running all neural networks aggregating their prediction, one obtains the best-in-class uncertainty estimation at the cost of computational investment.
In deep learning technology, a “mask” is a way to drop/hide artificial neurons, thus generating several slightly different model architectures, allowing a single model to mimic ensemble behaviour.
Masksembles can generate various models within which MC-Dropout and Deep Ensembles are extreme cases. It joins MC-Dropout’s light computational overhead and Deep Ensembles’ performance. Using many masks approximates MC-Dropout while using a set of non-overlapping, completely disjoint masks yields an Ensemble-like behaviour.
The Masksembles model defines a spectrum of model configurations of which MC-Dropout and Deep Ensembles can be seen as extreme cases. How does one model grade into another? The figure shows the transition from Ensembles to MC-Dropout. The points with green (MC-Dropout) and red (Emsembles) colours in the figure denote extreme cases that correspond to these models. In contrast, the yellow point represents an optimal parameter choice one could choose for a specific computational cost vs performance trade-off.
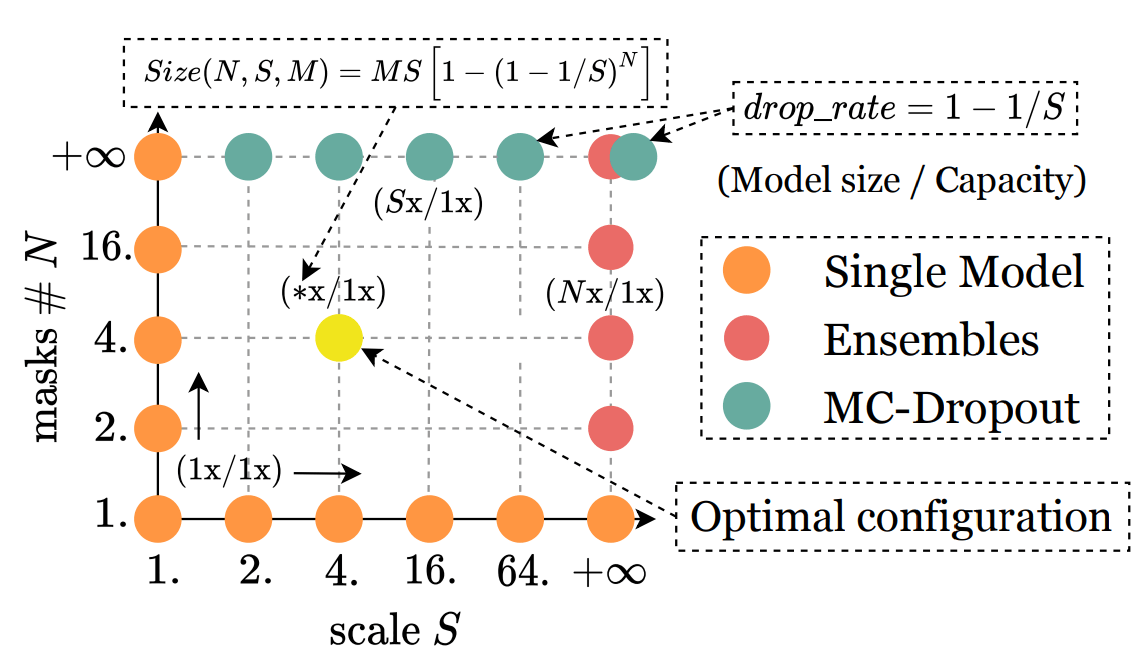
The three key parameters here are:
- N - the number of masks;
- M - number of ones in each mask;
- S - the scale that controls the overlap, given N and M.
Here, M is fixed while the number of masks N and the scale S vary.
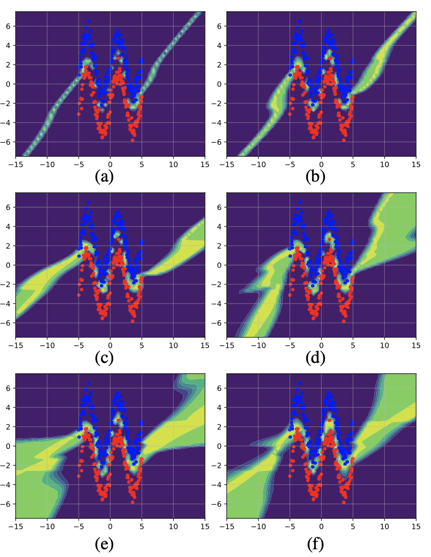
Another illustrative example is the transition to Ensembles transition via Masksembles is the following. The prediction task here is to classify the red Vs blue data points drawn in the [−5, 5] range from two sinusoidal functions with added Gaussian noise. The background colour in the figure depicts the entropy assigned by different models to individual points on the grid. Low entropy is represented in blue and high entropy is represented in yellow.
The figure ranges from (a) Single model to (b) – (e) Masksembles models with different parameters and finally (f) – Ensembles model.
For high mask-overlap values, Masksembles behaves almost like a Single Model, compare (a) and (b) but starts acting more and more like Ensembles as the mask-overlap value decreases, compare (e) and (f).
The Role of Calibration in Uncertainty Quantification
Calibration is adjusting a model's predictions to align more closely with the true values of the data. In uncertainty, calibration refers to the accuracy of a model's predicted probabilities or confidence scores. A calibrated model will produce predicted probabilities consistent with the outcomes' true frequencies.
There are several methods for calibrating a model, including the following three:
- Platt scaling involves fitting a logistic regression model to the data's predicted probabilities and true labels. The coefficients of the logistic regression model are used to adjust the predicted probabilities so that they align more closely with the true frequencies of the outcomes.
- Isotonic regression involves fitting a non-parametric model to the data's predicted probabilities and true labels. The model is constrained to be non-decreasing, which ensures that the predicted probabilities align more closely with the true frequencies of the outcomes.
- Temperature scaling: This method involves applying temperature scaling to the predicted probabilities. The temperature parameter is used to control the level of confidence in the predictions. A higher temperature will result in more confident (less calibrated) predictions, while a lower temperature will result in less confident (more calibrated) predictions.
Formal Discussion on Calibration
Suppose a model F(x) produces a probability p for each class c for an input x. We have a dataset D with n samples, so that D={(x₁,y₁),(x₁,y₁),...,(xₙ,yₙ)}, where "yᵢ" is the true label of the ith sample.
The calibration of the model can be measured by several metrics like Brier score, Log loss, and Expected Calibration Error (ECE). We will give the definitions here.
- The Brier score is a measure of the accuracy of probabilistic predictions. It is defined as the mean squared error between the predicted probabilities and the true labels, given by: Brier = 1/n ∑(y - F(x))²
- The Log loss measures the performance of a classification model whose output is a probability value between 0 and 1. The log loss is defined as: log loss = -1/n ∑( y log(F(x)) + (1-y) log(1-F(x)) )
- The Expected Calibration Error (ECE) measures the difference between the predicted probabilities and the true frequencies of the outcomes. It is defined as: ECE = 1/n ∑ |F(x) - y| * |F(x) - y|
These are some of the ways to measure the calibration of a model. By minimizing these metrics, we can calibrate the model and improve the accuracy of its probabilistic predictions.
For example, the authors used CIFAR10, one of the most popular benchmarks for uncertainty quantification. CIFAR10 was collected by Alex Krizhevsky, Vinod Nair, and Geoffrey Hinton. The CIFAR-10 dataset consists of 60'000 32 x 32 colour images in 10 classes, with 6'000 images per class. Training data are 50'000 images, while there are 10000 test images. The dataset is divided into five training data batches and one test batch, each with 10'000 images. The test batch contains exactly 1'000 randomly-selected images from each class. The training batches contain the remaining images in random order, but some may contain more images from one class than another. Between them, the training data batches contain exactly 5'000 images from each class.
The dataset is relatively small-scale, and huge models easily overfit the data. The authors placed dropout layers before all the convolutional and fully connected layers in the MC-Dropout model. The authors evaluated model accuracy and Expected Calibration Error on a "corrupted" version of CIFAR10.

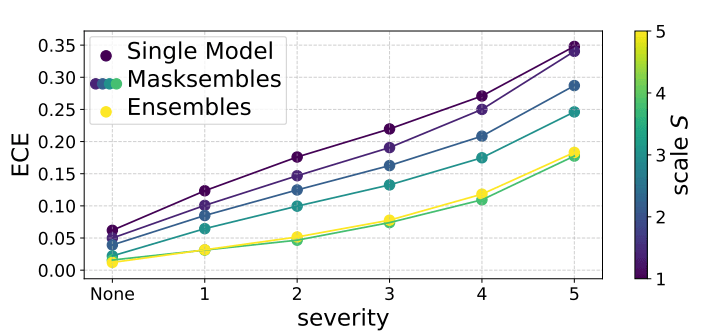
The following image shows the Expected Calibration Error (ECE) as a function of the severity of image corruption. Each Masksembles curve corresponds to a different S parameter. In this experiment, force M×S remained constant, and S varied the range [1., 1.1, 1.4, 2.0, 3.0]. Larger values of S correspond to more ensembles-like behaviour.
Conclusion
Neural Concept already provides the possibility, even for non-specialists, to have confidence levels for predictions.
The type of advanced research exposed in the last section will bring further benefits to engineers in terms of high performance and low computational costs.
Thus, at Neural Concept, we will continue to sustain engineers facing an important question – “am I sure about my predictions”?
Bibliography
Nikita Durasov, Timur Bagautdinov, Pierre Baqué, Pascal Fua (Computer Vision Laboratory, EPFL and Neural Concept): «Masksembles for Uncertainty Estimation», arXiv:2012.08334v1 [cs.LG], 15 Dec 2020