Set new industry standards with Engineering Intelligence








The end-to-end platform for high-performance engineering teams.
Powered by the world's leading proprietary 3D AI core.
Take better products from concept to production at lightning speed.
Engineering companies are under unprecedented pressure to design and deliver better products faster. Neural Concept’s platform brings Data Scientists, CAE and CAD engineers together around a single platform to boost your product development and innovation with industry leading 3D Deep-Learning and simulation capabilities.

Boost your product engineering
The end-to-end platform is designed to work with you familiar CAE and CAD softwares. 3D visual feedback, a collaborative environment and LLM guidance help 10x the impact of engineers. With 3D deep learning, Neural Concept accelerates the way engineers conceptualize, design and validate products – from concept to market.

Interactive, collaborative and scalable
CAE engineers are empowered to 10x their productivity and impact by making Engineering Intelligence the central paradigm of the design process. They build and deploy powerful workflows at scale, while remaining seamlessly connected to their existing ecosystem.

Redefine design timelines
Accelerate the adoption of Engineering Intelligence across the company. As a result, AI-designed products are brought to the market up to 75% faster.

Outcompete the competition
NCS is used by 60+ OEMs and several Formula One Teams to accelerate innovation and increase their competitive edge. Read about how Williams F1 Team use NC here in TechCrunch.







Success stories
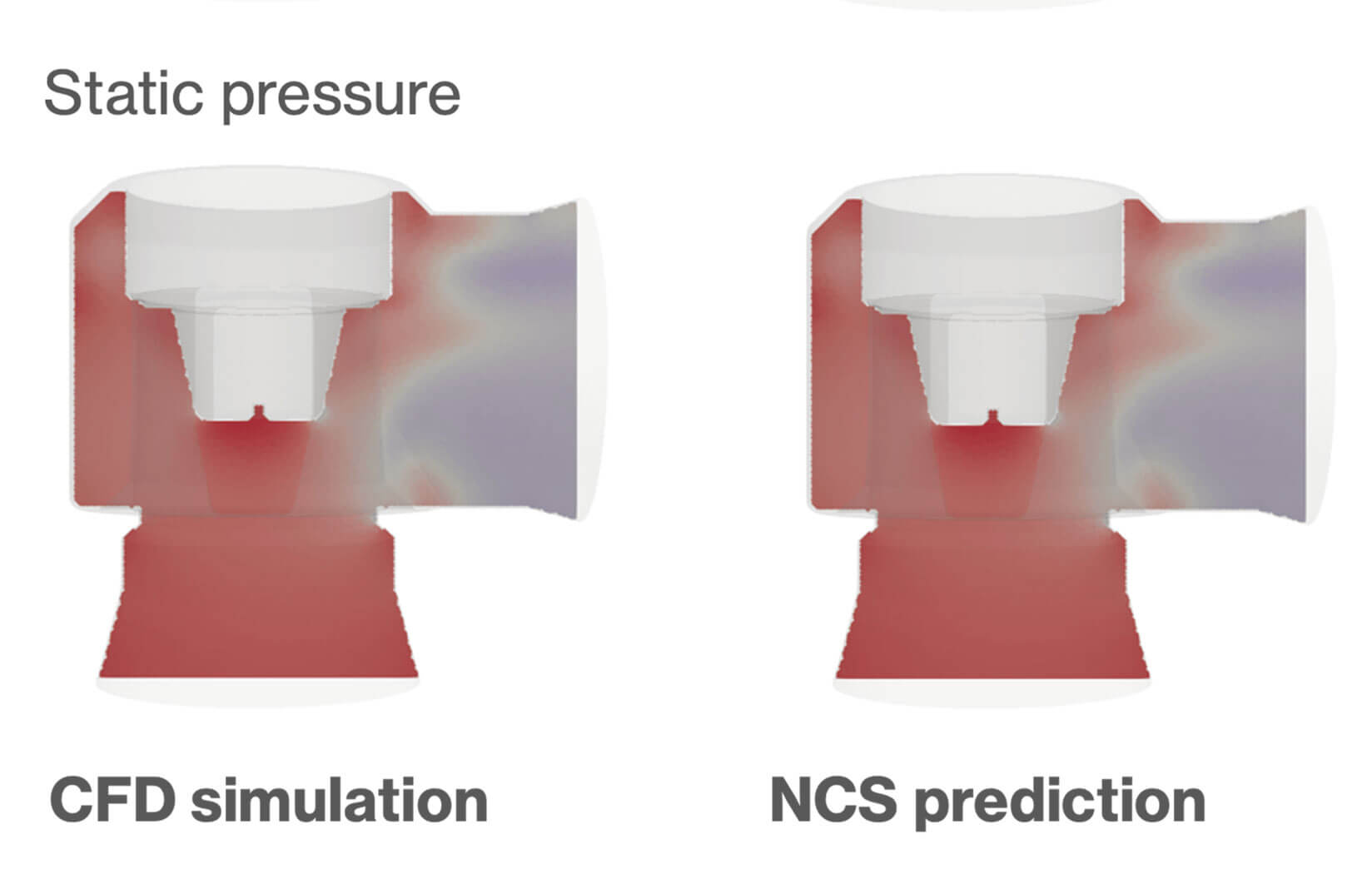
Enhancing check valve design with Danfoss
We collaborated with Danfoss to integrate NCS into their product design workflows. Through NCS models, they optimize check valve performance, achieving approximately 10% improvement in mass flow rate.
From weeks to a day: Mitsubishi Chemical Group accelerating material characterization
MCG has fully deployed NCS in their experts' and designers' workflow and is now able to provide a qualified answer to their customers within a single day instead of several weeks with their previous traditional process.
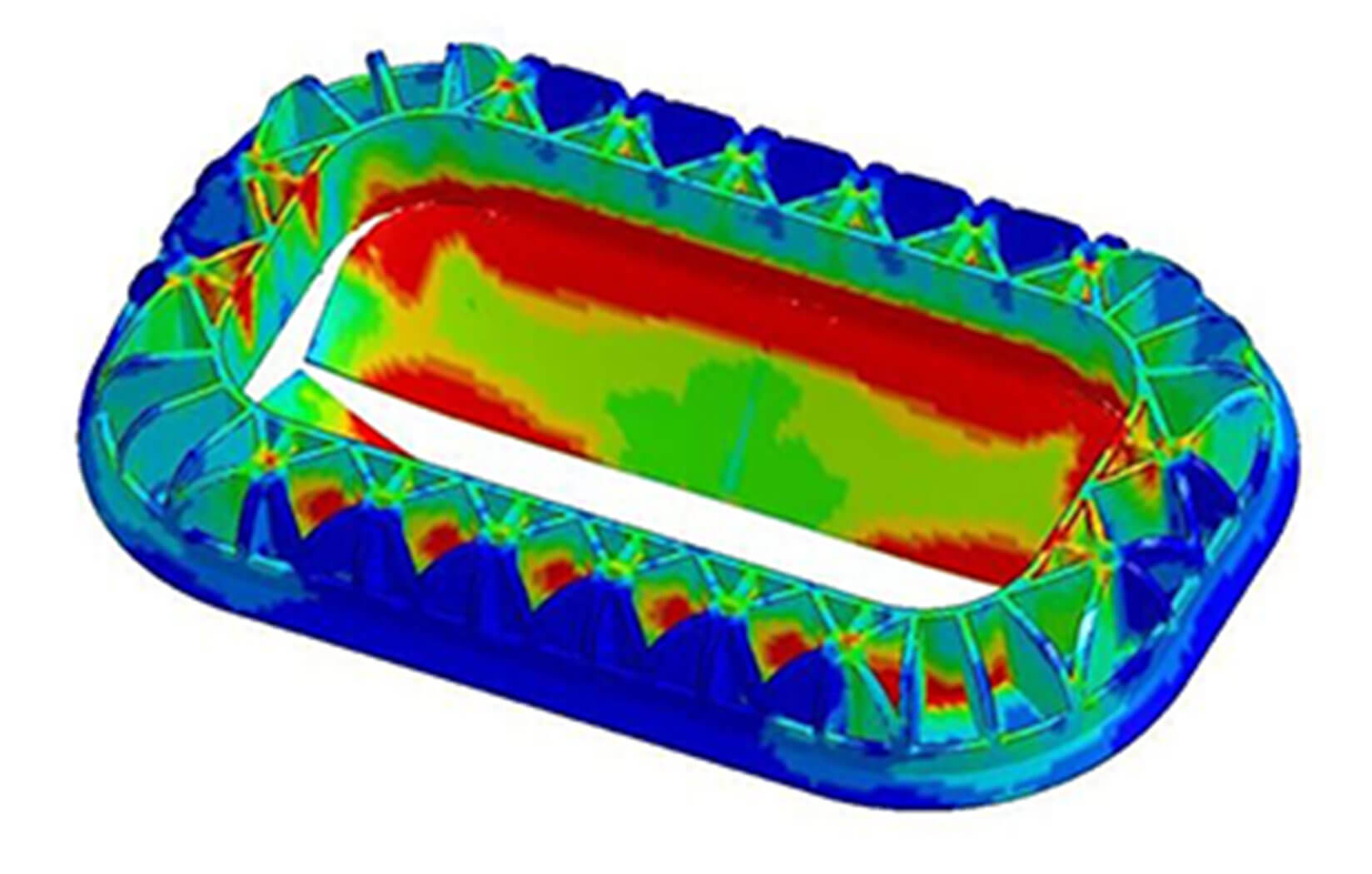
Improving crash box performance by 10% with DLR
The German Aerospace Center (DLR) partnered with us to enhance the design of crash boxes for novel vehicles using deep learning, showcasing the transformative potential of NCS for sustainable and cost-effective vehicle concepts.

